


























Допустим, вы решили крутить большую языковую модель не в облаке, а у себя — на сервере, рабочей станции или ноутбуке. Сразу встает вопрос: через какой инструмент это делать. На рынке сегодня три заметных игрока: Ollama, vLLM и LM Studio. Каждый умеет одно и то же — поднять LLM локально и дать к ней доступ через API или интерфейс.
Разница в том, ради чего инструмент создавался. Ollama делает ставку на простоту, vLLM — на максимальную производительность под нагрузкой, LM Studio — на графический интерфейс без терминала. В этой статье разберем, чем эти три движка отличаются на практике и какой из них подходит под ваш сценарий.
Зачем запускать LLM локально на своем сервере
Запустить LLM локально имеет смысл по нескольким причинам, и все они сводятся к одному — вы получаете контроль над данными, над поведением модели, над расходами и над временем отклика.
Приватность и стоимость
Первая причина — приватность и комплаенс. Когда сеть крутится в периметре компании, никакие пользовательские обращения, медицинские карты или платежные операции не уходят к стороннему провайдеру. Это особенно важно для финтеха, банков и медицинских сервисов, а еще для проектов под ФЗ-152 или Приказ ФСТЭК. Локальная LLM закрывает класс вопросов от службы безопасности и юристов одним решением.
Вторая причина — стоимость. Облачные API удобны на старте: платишь по факту использования. Но как только нагрузка переваливает за 100 тысяч обращений в день, ежемесячный счет от провайдера легко уходит в десятки тысяч долларов. Своя инфраструктура на стабильной нагрузке окупается за несколько месяцев.
Контроль и предсказуемая скорость
Третья причина — контроль над тем, как именно ведет себя нейросеть. На своем сервере у вас в руках сама модель и квантизация (степень сжатия весов), и можно применить файнтюнинг под свои данные. Например, дообучить ее на корпоративных документах. И вы перестаете зависеть от того, что вендор завтра поднимет цены или закроет API.
Четвертая причина — предсказуемая latency. Локальный inference по внутренней сети дает стабильные 50–100 миллисекунд на токен без скачков. Облачный API через интернет — это уже 200–500 миллисекунд плюс провалы во время пиковой нагрузки. Для интерактивных сценариев и RAG-систем такая разница бывает критичной.
Ollama: простой старт и где упирается в потолок
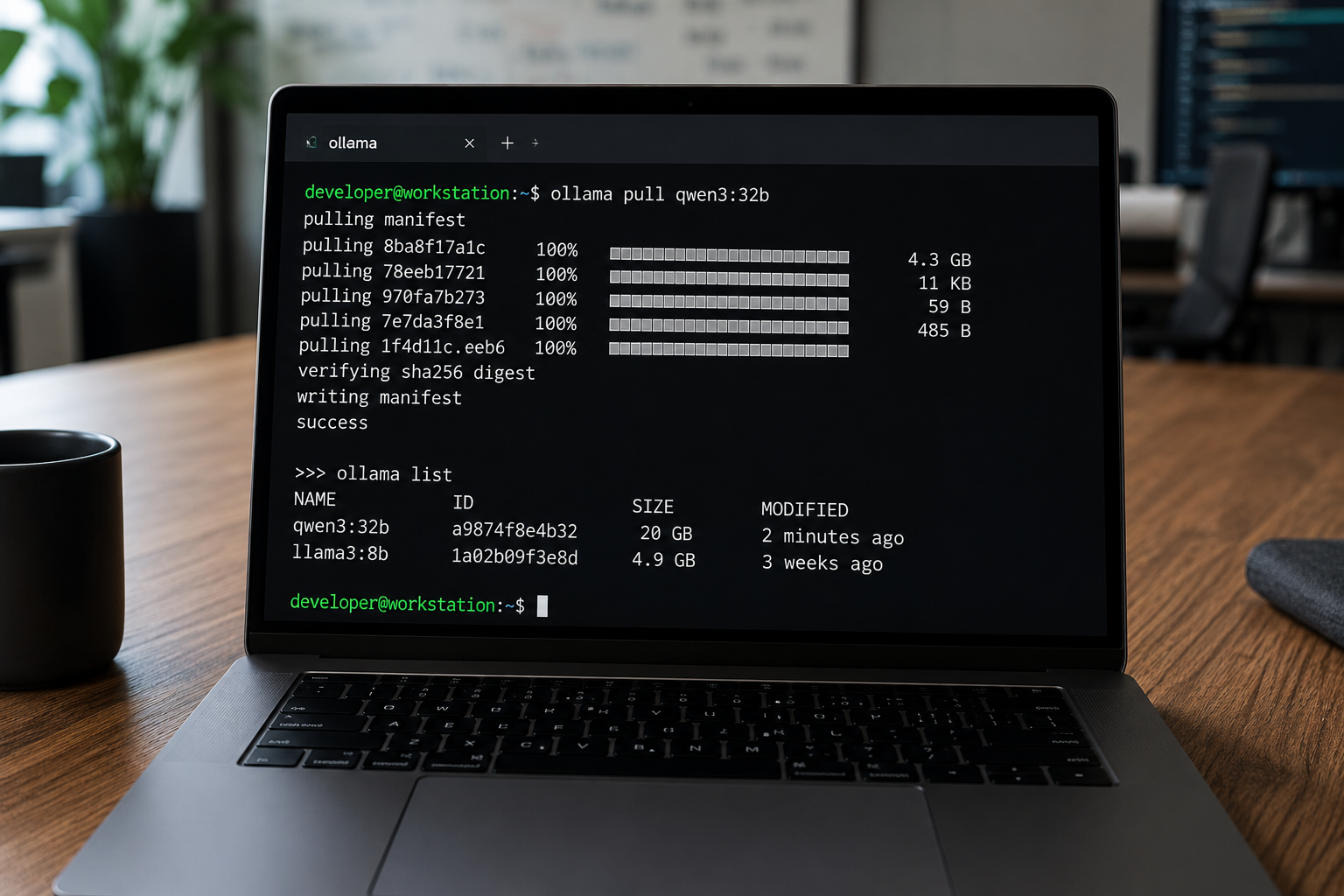
Если вы только начинаете запускать LLM у себя, то на вопрос «Ollama что это» ответ простой. Это легкий CLI-инструмент, который позволяет одной командой скачать любую языковую модель и сразу ее использовать. По сути это удобная обертка над открытой библиотекой llama.cpp, которая умеет inference квантованных моделей и работает почти на любом железе.
Что умеет Ollama и кому подходит
Главное достоинство — никакой подготовки. Скачиваете установочный пакет под Linux, macOS или Windows, выполняете ollama pull qwen3:32b — через пару минут у вас локальный сервер с сетью. Параллельно поднимается OpenAI-совместимый API и любой клиент под OpenAI (LangChain, LlamaIndex, Open WebUI, Continue.dev) подключается без правки кода. По железу поддержка широкая: NVIDIA через CUDA, AMD через ROCm и Apple Silicon через Metal. Это удобно, когда у людей в команде разные машины.
Где Ollama упирается в потолок
Ограничения становятся заметны, как только нужно обслужить больше одного пользователя. При 16 и более параллельных обращениях общая пропускная способность почти не растет, и в среднем по бенчмаркам Ollama проигрывает vLLM в 3–16 раз. Причина в архитектуре: под капотом нет современных оптимизаций для параллельной обработки — ни PagedAttention, ни continuous batching. Поэтому видеокарта между запросами часто простаивает.
Multi-GPU тоже работает, но без оптимизаций tensor parallelism. Большая модель просто разрезается на блоки между картами. Этот режим работоспособен, но далеко от того, что выжимают специализированные движки.
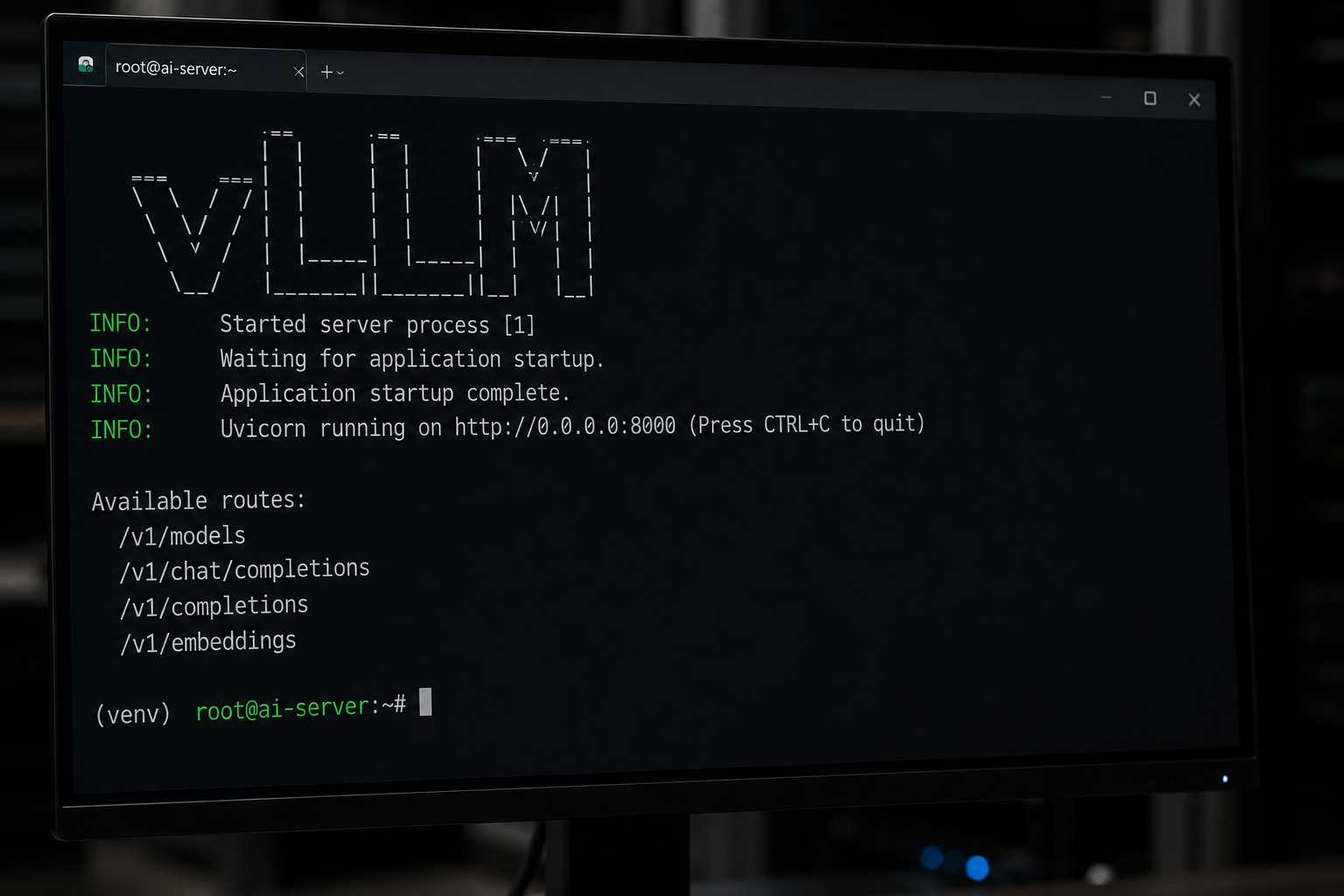
vLLM: продакшен-движок с PagedAttention
vLLM — это open-source движок, который изначально разрабатывали в университете Беркли с одной целью: выжать максимум производительности из дорогого GPU при concurrent-нагрузке. По бенчмарку Red Hat Developer 2025 на той же Llama 3 8B Q4 throughput у vLLM в 3.23 раза выше при 128 concurrent, а на Llama 3 70B при 256 concurrent разрыв доходит до 16x. Эти цифры объясняются тремя ключевыми механиками.
Что внутри vLLM простыми словами
PagedAttention — это умное управление видеопамятью. Аналогия простая: ОС не выделяет программе оперативную память сплошным куском, а режет ее на страницы и подкачивает по требованию. PagedAttention делает то же самое с KV-cache (промежуточным кешем под каждый токен в контексте). Память не фрагментируется, и в ту же видеокарту помещается заметно больше параллельных запросов.

Continuous batching решает другую проблему. Классические движки обрабатывают обращения по очереди: пока одно не закончило генерацию, новое ждет. vLLM делает иначе — на каждом шаге он подмешивает токены из новых обращений в общий батч. GPU не простаивает, и за счет этого получается основной отрыв при параллельной нагрузке.
Третий механизм — prefix caching. Если у нескольких запросов есть общая часть промпта (системный промпт или фрагмент RAG-контекста), движок считает ее один раз и переиспользует. На реальных нагрузках это снижает latency первого токена на 20–40 процентов.
Кому подходит и какие ограничения
Из коробки vLLM поддерживает safetensors с Hugging Face, AWQ-квантизацию (квантизация снижает VRAM в 2–4 раза), tensor parallelism через NVLink и OpenAI API на порту 8000. Разворачивается через Docker и Kubernetes, есть интеграция с MCP и RAG через FastAPI. Главное ограничение — работает только на NVIDIA с CUDA. На AMD, Apple Silicon и CPU запустить нельзя. Установка сложнее Ollama: нужно правильно подобрать версию CUDA и драйвер.
По сценариям vLLM подходит для продакшен-инференса с нагрузкой от 4 параллельных запросов и для команд от 5 разработчиков с одной shared-моделью. Под такие сценарии разумно собирать GPU-сервер с одной A100/H100 80GB или несколькими картами с NVLink — это снимает потолок по concurrent.
LM Studio — графический интерфейс для запуска LLM
LM Studio — это десктопное приложение с графическим интерфейсом для запуска LLM на своей машине. Технически оно тоже опирается на llama.cpp, но добавляет сверху удобный визуальный слой: окно с чатом, поиск моделей по Hugging Face, настройки в интерфейсе и встроенный Server-mode.
Главные плюсы и поддержка железа
Самый заметный плюс — GUI без терминала. Чтобы загрузить модель, достаточно одного клика по карточке. Параметры генерации (температура, top_p, системный промпт) настраиваются прямо в окне. Поддерживается формат GGUF и MLX (последний — для Apple Silicon). Server-mode превращает LM Studio в локальный OpenAI-совместимый API-сервер на http://localhost:1234/v1, и клиенты подключаются так же, как и к Ollama.
По GPU поддержка получилась самая широкая из трех инструментов: NVIDIA через CUDA, AMD и Intel через Vulkan, Apple Silicon через Metal. Такое сочетание встречается редко и особенно ценно при разнородном парке машин.
Кому подходит и где не сработает
Ограничения у LM Studio в двух плоскостях. Первое — лицензия проприетарная, для коммерческого использования нужен enterprise-план. Второе — низкий concurrent-throughput: потолок 4–8 параллельных запросов, поэтому для production программа не подходит.
Зато LM Studio отлично подходит разработчикам без привычки к терминалу и ML-инженерам, которые перебирают десятки моделей в день. Для демонстраций и обучения тоже хороший вариант. Если приложение становится основным инструментом, имеет смысл поставить его на отдельную AI-workstation с RTX 4090 24GB или Apple Silicon Pro/Max.
Сравнительная таблица: GUI/CLI, throughput, форматы, multi-GPU, API + бенчмарк vLLM vs Ollama
vLLM vs Ollama в одной таблице с LM Studio в третьей колонке — самый быстрый способ увидеть разницу между движками одним взглядом.
Цифры из бенчмарков объясняют, что стоит за этими параметрами на практике. По данным Red Hat Developer 2025 на Llama 3 8B Q4 throughput у vLLM в 3.23 раза выше при 128 concurrent. На Llama 3 70B при 256 concurrent разрыв доходит до 16x по суммарным токенам в секунду.
По замерам Robert McDermott (Medium), на одиночном запросе Ollama чуть быстрее по TTFT — времени до первого токена: 50–80 мс против 80–150 мс. Причина в том, что есть фаза warm-up для PagedAttention, которая на одиночном обращении только мешает. Но как только параллельных запросов становится 4 и больше, движок уверенно уходит вперед за счет continuous batching.
Если резюмировать: vLLM забирает сценарии с concurrent от 4 запросов, Ollama быстрее на одиночных, LM Studio выигрывает там, где вместо API нужен интерфейс. Когда нагрузка серьезная и одной картой не обойтись, под vLLM собирают сервер с NVLink — обмен между GPU там в разы быстрее, чем по PCIe.
Ollama vs vLLM vs LM Studio — выбор по сценарию
Ollama vs vLLM vs LM Studio — выбор всегда нужно вести от сценария, а не от попытки сразу взять самый мощный инструмент. Сначала ответьте: как вы планируете использовать модель — один на машине, командой или в продакшене с реальной нагрузкой.
Соло-разработчик и команда
Для соло-разработчика, у которого один человек, одна модель и нет concurrent-запросов, выбор очевиден — Ollama. Установка за 10 минут, привычный CLI и совместимость с любыми клиентами через OpenAI API. Если хочется чат и кнопки, поверх Ollama ставится Open WebUI или сразу берется LM Studio. Функционально это одно и то же, разница только в интерфейсе.
Для команды из 5–15 разработчиков обычно подходит гибрид: на общем сервере поднимается vLLM с одной мощной моделью под основной API, а на ноутбуках разработчики держат LM Studio для тестов на легких сетях.
Production и работа без GPU
Production с реальной concurrent-нагрузкой — это территория vLLM без альтернатив. Continuous batching и PagedAttention дают в 3–16 раз больше throughput, и эта разница переводится в число клиентов на одну карту. Сюда же стоит сразу заложить multi-GPU через NVLink и нормальную сеть между нодами — иначе bottleneck быстро смещается с GPU на сетевой обмен.
Inference на CPU без видеокарты — отдельный сценарий. Тут запускается либо Ollama через llama.cpp, либо LM Studio через Vulkan-offloading. Скорость 2–10 токенов в секунду — для серьезного использования мало, для прототипа хватает. На CPU vLLM не идет в принципе.
Требования к серверу для каждого инструмента
Сервер под каждый из трех инструментов собирается по своей логике, потому что нагрузка на железо у них разная.
Сервер под Ollama
Под Ollama железо подбирается без особых требований — это серверный CLI, его ставят на стандартную инфраструктуру. Минимум — RTX 4060 16GB для Q4-моделей до 13B параметров. RTX 4090 на 24GB закрывает Llama 3 8B в FP16 и Mistral Small Q4. Для 70B-сетей в Q4 уже нужна A100 80GB или связка из двух RTX 4090. Системные требования скромные: 32 ГБ оперативной памяти и обычный SSD.
Рабочая станция под LM Studio
Под LM Studio класс железа другой — это десктопное приложение, поэтому собирают рабочую станцию, а не сервер. Подойдет RTX 4090 24GB или Mac M2/M3 Pro/Max. Vulkan позволяет запускать инференс на AMD-картах вроде RX 7900 XTX. CPU-режим тоже доступен, но 2–5 токенов в секунду хватит только на легкие сети.
Сервер под vLLM и production-нагрузку
vLLM требует совсем другого подхода. Из видеокарт поддерживается только NVIDIA: A100 на 40 или 80 ГБ либо Hopper. Из софта понадобятся CUDA версии 12 и выше, NVIDIA-драйвер 535+ и Docker для удобства развертывания. Для concurrent-нагрузки от 16 запросов NVLink между картами уже не опция, а обязательное требование.
Без него обмен идет через PCIe в 5–10 раз медленнее, и continuous batching теряет смысл. Под production-сценарий имеет смысл сразу подобрать сервер под локальный LLM с расчетом VRAM, NVLink и сетевой подсистемы.
Заключение
Ollama — для старта и соло-разработки. LM Studio — для GUI-задач и команд без серверной инфраструктуры. vLLM — для продакшена с concurrent-нагрузкой. Часто рабочее решение — гибрид: vLLM держит основной production-API, LM Studio дает разработчикам интерфейс, Ollama выручает на ноутбуках.
После выбора инструмента и модели остается последний шаг — собрать целевое оборудование для AI с правильным числом GPU, охлаждением и сетевой подсистемой.
Часто задаваемые вопросы о запуске LLM локально
Можно ли запустить vLLM без NVIDIA GPU?
Нет. vLLM завязан на CUDA и PagedAttention, а они работают только на видеокартах NVIDIA. На AMD есть экспериментальная поддержка через ROCm, но в production пока не годится. На Apple Silicon движок не запускается. Если NVIDIA недоступна, остаются Ollama или LM Studio.
Чем GGUF отличается от safetensors?
GGUF — формат для квантованных моделей, который используют llama.cpp, Ollama и LM Studio. Оптимизирован под CPU и потребительские видеокарты, поддерживает квантизации Q4_K_M, Q5_K_M и Q8_0. Safetensors — формат с Hugging Face, в нем хранятся базовые веса в FP16 или BF16. vLLM работает с safetensors напрямую и поддерживает AWQ-квантизацию.
Поддерживает ли Ollama OpenAI-совместимый API?
Да, совместимость покрывает /chat/completions, /completions и /embeddings. Любой клиент под OpenAI API подключается без изменений в коде.
Какой инструмент выбрать для команды из 10 разработчиков?
Зависит от того, нужна ли общая модель. Если все обращаются к одной параллельно — vLLM на shared-сервере с NVLink. Если каждый запускает у себя — Ollama или LM Studio. Часто рабочий вариант — гибрид: vLLM держит shared production-inference, а LM Studio стоит на ноутбуках для тестов.
Можно ли использовать LM Studio в продакшене?
Технически да, через Server-mode. Но это не рассчитано на продакшен: лимиты на concurrent (потолок 4–8), нет встроенного балансировщика нагрузки, проприетарная лицензия. Для нагрузки от 4 параллельных запросов в секунду разумнее vLLM.
Как vLLM работает с continuous batching?
Движок не ждет окончания одного запроса. На каждом шаге генерации токены из новых обращений подмешиваются в общий батч, и видеокарта не простаивает. Именно за счет этого получается 3–16 раз больше throughput при concurrent-нагрузке против Ollama.
Поддерживает ли Ollama Multi-GPU?
Поддерживает, но ограниченно. Сеть распределяется по нескольким GPU без оптимизаций tensor parallelism. Этот режим действует, но дает 2–4x проигрыш конкуренту на той же конфигурации. Для серьезного multi-GPU сценария однозначно vLLM.
Что выбрать для inference на CPU без GPU?
LM Studio через Vulkan-offloading или Ollama через llama.cpp. Скорость на современных Xeon или EPYC — 2–10 токенов в секунду. На GPU для сравнения — 50–200 токенов в секунду. vLLM на CPU не запускается: PagedAttention завязан на GPU.



