


























Когда в компании поднимают второй или третий сервер 1С, обычно ждут, что нагрузка сама поделится между ними поровну. На практике балансировка нагрузки 1С «из коробки» работает прилично только до первой серьезной задачи: один узел оказывается перегружен закрытием месяца и тяжелыми отчетами, а соседние простаивают.
Дальше разберем, как платформа распределяет сеансы между rphost, когда автоматики уже мало и нужны ручные правила, как добавить аппаратный балансировщик в крупный кластер и какие метрики ловить, чтобы вовремя замечать проблемы.
Как кластер серверов 1С балансирует нагрузку «из коробки»
По умолчанию платформа раздает новые сеансы между рабочими серверами кластера по простой логике: смотрит на текущую загрузку каждого узла и выбирает наименее занятый. Внутри узла сеансы расходятся между рабочими процессами rphost. Один rphost обычно держит 30–50 пользователей, и при росте нагрузки платформа поднимает дополнительные процессы — в пределах того, что прописано в параметрах кластера.
Все это видно в консоли администрирования: для каждого узла там показывается число активных сеансов, количество rphost, занятая память и нагрузка на процессор. Картина вроде бы простая. Но автоматическое распределение умеет считать только новые сеансы — а вот «тяжелый» сеанс, который уже сел на конкретный узел и теперь крутит трехчасовое закрытие месяца, никто никуда не двигает. То же самое с регламентными заданиями: они раздаются по узлам по очень общим правилам, и без ручной настройки могут осесть все на одном сервере.
Когда автобалансировки недостаточно: типичные симптомы
Симптомы, что автобалансировки не хватает, узнаются легко. На одном узле кластера утилизация процессора стабильно держится 80–90%, на втором — 20–30%. Бухгалтерия жалуется, что отчеты у тех, кто открыл базу первыми, идут в два раза дольше, чем у тех, кто подключился позже. Регламентные задания типа «закрытие месяца» или «пересчет себестоимости» уходят в ночь и тормозят даже ту работу, которая в это время идет в базе.
Отдельная история — СУБД как общее узкое место. Сколько ни разноси сеансы по серверам кластера, упираются они в одно и то же — в общий сервер баз данных. В кластере серверов 1С балансировка нагрузки имеет смысл только тогда, когда диск, процессор и память самой базы данных не перегружены. Если СУБД уже на пределе, никакая балансировка не поможет — нужно сначала разгрузить именно ее, а потом уже играться с распределением сеансов.

Автоматическое распределение нагрузки: что настроить в первую очередь
В консоли администрирования у каждого узла есть три параметра, которые сильно влияют на автоматическое распределение нагрузки. Первый — «Допустимый объем памяти рабочих процессов»: обычно ставится 70–80% от общей памяти сервера, чтобы оставить запас для операционной системы. Второй — «Безопасный расход памяти за один вызов»: страхует от того, что один тяжелый отчет съест всю память узла. Третий — «Время простоя» (по умолчанию 600 секунд) и «Время жизни сеанса» (обычно 86 400, то есть сутки): настраивают, как быстро освобождаются ресурсы под новых пользователей.
Веса и приоритеты рабочих серверов — отдельный инструмент. По умолчанию каждый узел получает вес 100. Если один сервер мощнее остальных, ему ставят вес 200 — и он получает в два раза больше новых сеансов. Слабому узлу можно поставить вес 50 и фактически использовать его как «резерв». Дальше идет ручная корректировка, для которой у платформы есть специальный механизм требования назначения функциональности.
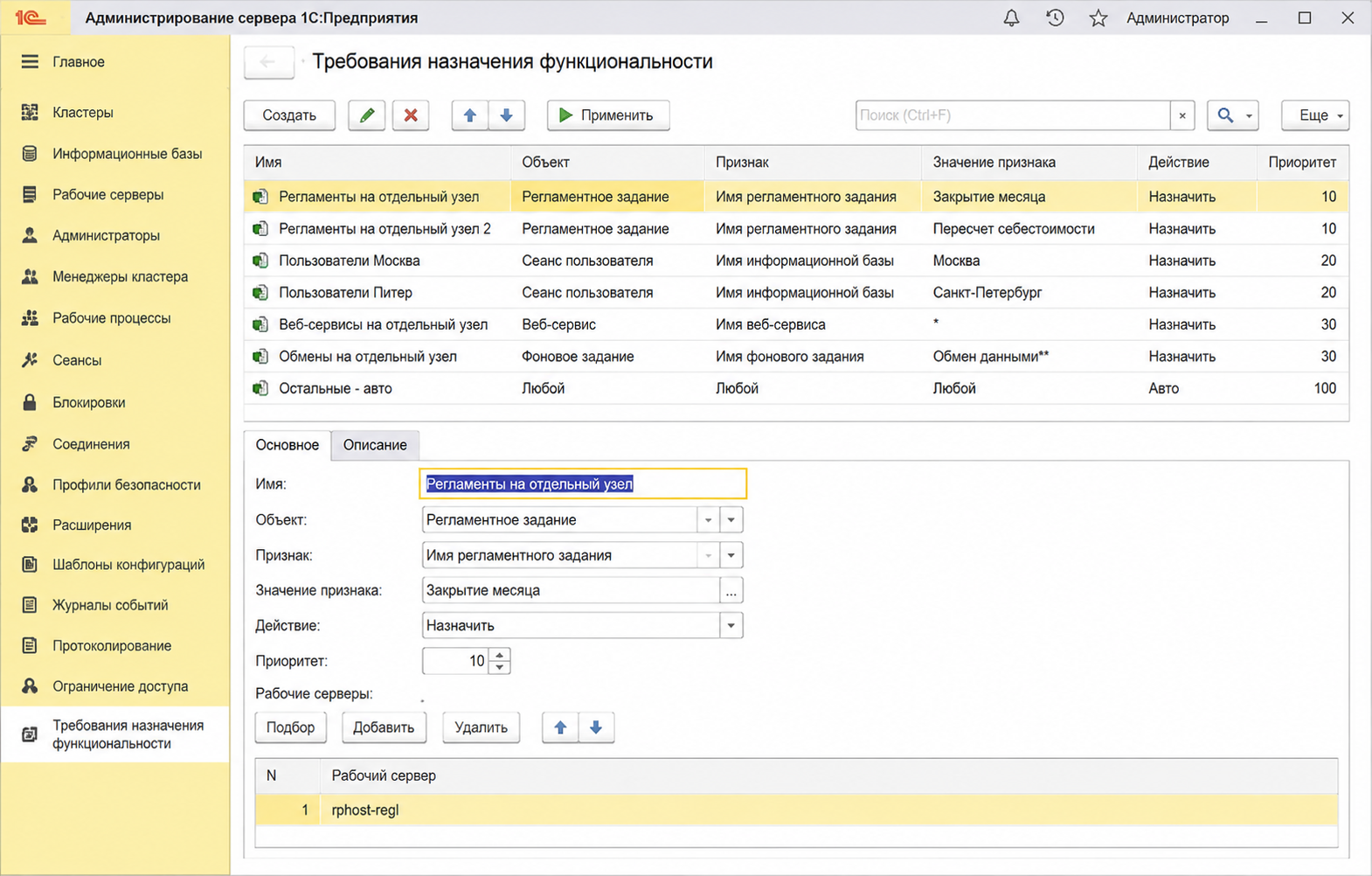
Ручная корректировка распределения через правила
Требования назначения функциональности — это правила, которыми администратор кластера говорит платформе: вот эту нагрузку отправляй сюда, а вот эту — туда. Каждое правило состоит из объекта (сеанс пользователя, фоновое задание, регламентное задание, веб-сервис), признака (имя информационной базы, имя пользователя, тип задания) и действия (Назначить, Не назначать, Авто).
В типовом сценарии правилами выносят регламентные задания на отдельный узел, чтобы тяжелое закрытие месяца не мешало работе обычных пользователей. Можно разделить нагрузку по филиалам: пользователи Москвы — на один сервер, пользователи Питера — на другой.
Можно отделить веб-сервисы и обмены с другими базами в собственный узел, чтобы их активность не задевала интерактивную работу. Создаются такие правила или через консоль администрирования, или через утилиту командной строки rac — для крупных кластеров второй вариант удобнее, потому что правила можно версионировать и применять скриптами.
Аппаратный балансировщик: когда нужен и как поставить
Встроенной балансировки платформы хватает примерно до пяти узлов и пары сотен одновременных пользователей. Дальше начинаются эффекты, которые без отдельного балансировщика лечить сложно: «прилипание» пользователей к одному узлу, рваная нагрузка при подключении большой группы людей, медленное переподключение при failover. На таких объемах перед кластером ставят аппаратный балансировщик или его программный аналог.

Самый частый выбор для 1С — HAProxy. Он бесплатный, отлично работает с долгими сеансами по протоколу TCP и умеет проверять живые узлы запросом на порт 1541 каждые пять-десять секунд. Из встроенных алгоритмов балансировки HAProxy для 1С обычно используют Round Robin (по очереди на каждый узел) или Least Connections (новый сеанс уходит туда, где сейчас меньше открытых подключений). Nginx тоже умеет балансировку TCP, но на длинных сеансах 1С HAProxy ведет себя стабильнее.
Рекомендуемая настройка для 1С — sticky session по исходному IP: она снижает количество переключений узлов и уменьшает накладные расходы на повторную инициализацию сеансов. При отказе узла сеанс все равно мигрирует на соседний — платформа 1С 8.3 поддерживает роуминг независимо от sticky session. Для крупных корпоративных внедрений берут аппаратный балансировщик F5 BIG-IP или его российские аналоги.
На том же хосте, где живет HAProxy, имеет смысл добавить 2–4 ядра и 8 ГБ RAM сверх требований кластера 1С — этого хватает на балансировщик с запасом и health-checks даже при сотнях одновременных подключений. Если планируется отдельный сервер под балансировщик и центральный rmngr, сервер с учетом нагрузки подбирают сразу по целевому числу пользователей и количеству узлов в кластере.
Балансировка регламентных и фоновых заданий
Регламентные задания — отдельная боль для любого кластера 1С. По умолчанию платформа раздает их по любому свободному узлу, и в результате тяжелый пересчет себестоимости легко садится на тот же сервер, где работают обычные пользователи. Стандартный прием — выделить один из узлов кластера специально под регламенты и перенаправить туда все тяжелые задания через требования назначения функциональности. Это особенно важно для розничных сетей, где нужен сервер для 1С на 100 пользователей и где закрытие смены не должно ломать работу касс.
Веб-сервисы и WS-соединения для обменов между базами тоже стоит выносить отдельно. У них своя специфика: они держат соединения долгими сериями, могут давать резкие всплески нагрузки и при этом часто работают в фоне без прямого участия пользователя. Узел под веб-сервисы обычно требует меньше памяти, но больше пропускной способности сети.
Метрики и мониторинг балансировки
Главная метрика для оценки балансировки — Apdex (показатель удовлетворенности пользователей скоростью). На сайте gilev.ru есть бесплатный инструмент, который собирает Apdex из информационной базы и показывает, где у вас зеленая, желтая и красная зоны. Цифра ниже 0,85 — повод смотреть в технологический журнал 1С. Журнал включается через файл logcfg.xml и пишет детальные события: длительность каждого вызова, ожидание блокировок, утилизация rphost, создание и освобождение сеансов.
Для системного мониторинга кластера обычно поднимают связку Prometheus и Grafana с экспортером метрик через утилиту rac. На дашбордах смотрят утилизацию процессора и памяти по каждому узлу, число активных rphost, очередь блокировок СУБД и количество сеансов на каждом сервере. Регулярный аудит ИТ-инфраструктуры с проверкой этих метрик помогает поймать перекос балансировки до того, как пользователи начнут жаловаться.
Сравнительная таблица: способы балансировки в кластере 1С
Чтобы было проще выбрать подход под свой масштаб, основные способы балансировки сравнили в таблице.
Из таблицы видна логика выбора. До 2–3 узлов хватает встроенного автоматического распределения. От 3 до 5 узлов уже нужны ручные правила требования назначения функциональности. Свыше 5 узлов или 200 пользователей — добавляется внешний балансировщик уровня HAProxy или F5.
Часто задаваемые вопросы о балансировке 1С
Как платформа 1С выбирает хост для нового сеанса?
Берет рабочий сервер с наименьшей загрузкой, учитывает вес и приоритеты узла, проверяет, не запрещен ли данный тип сеанса требованиями назначения функциональности. Если все условия выполнены, новый сеанс уходит на этот узел.
Можно ли балансировать сеансы по типу пользователя?
Да, через требования назначения функциональности. Создается правило с признаком «имя пользователя» и нужное действие. Например, всех сотрудников бухгалтерии можно направлять на один узел, а всех сотрудников склада — на другой.
Sticky sessions нужны для 1С?
На внешнем балансировщике перед кластером — рекомендуется. Сеансы 1С долгие, и переподключение пользователя на другой узел в середине работы дает лишнюю нагрузку и обнуляет кэш. Привязка по исходному IP снижает количество таких переключений. Но при отказе узла платформа все равно мигрирует сеанс на соседний — sticky session ускоряет работу, а не отвечает за отказоустойчивость.
Что лучше: один мощный сервер или 3 средних в кластере?
Зависит от задач. Один мощный сервер дает максимальную скорость на каждом отдельном сеансе, но не защищает от простоя. Три средних сервера в кластере дают отказоустойчивость и возможность плавно расти по нагрузке, но требуют грамотной балансировки. Для большинства средних компаний три узла в кластере — практичнее.
Сколько rphost задавать на хост?
Стандартная отправная точка — 1 рабочий процесс на 30–50 пользователей. Для активных задач (закрытие месяца, тяжелые отчеты) — 2–3 rphost на узел. Конкретное число подбирается под объем памяти узла и характер нагрузки.

Заключение
Балансировка нагрузки в кластере 1С — это не одно решение, а лестница. Маленьким кластерам хватает встроенного автоматического распределения и аккуратной настройки rphost. По мере роста добавляются ручные правила требования назначения функциональности — для выноса регламентов, веб-сервисов и группировки пользователей по подразделениям.
Крупным внедрениям нужен внешний балансировщик HAProxy или аппаратный аналог. Конкретный следующий шаг — снять метрики Apdex и утилизации узлов, найти перекос и выбрать минимально достаточный инструмент.



